
Several readers have asked about plagiarism detection. So in today’s post I will talk about the tools I have been using, and some other tools that are available.
In a previous post, “What is Research Misconduct? Part 1: Plagiarism” I talked about the Office of Research Integrity (ORI), and their definition of the different types of science misconduct. ORI defines plagiarism as the “appropriation of another person’s ideas, processes, results, or words without giving appropriate credit“.
In other popular definition of plagiarism the term is specifically used for written or spoken text that include sentences written previously by others, without putting them between quotes (which I did above for the ORI definition), and without crediting the original author.
It is hard to screen the literature for papers that steal other person’s ideas or results, but it is a bit more easy to screen for papers that reuse other authors’ text.
So here are the tools I have been using.
Google Scholar
For free, manual, checking of small chunks of text, the search function in Google Scholar has been my most trusted tool. Scholar has access to the full text of almost all science papers, not just the abstract, and it will find exact matches only if you put your search term between quotes. For example, try “Marine mammals play essential roles in the marine ecosystem” in https://scholar.google.com/, and you should find exactly one paper that has that sentence. You might even recognize the first author 🙂

In fact, Google Scholar is what I used to find the plagiarized text that marked the beginning of my interest in science misconduct. I used a part of a sentence that I had written for a 2009 review published in Nutrition Reviews and instead of finding just my own paper, I found several other hits.
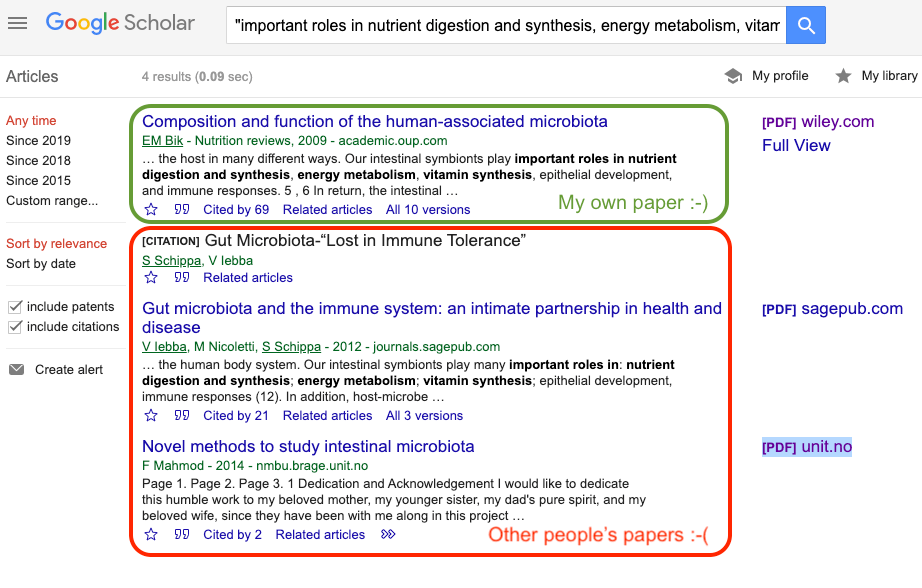
Note that my paper was published in 2009, while the other occurrences of my sentence were from 2012 and 2014. Note: Since I did this search in the spring of 2013, the thesis did not yet show up.
If I have found a sentence with 2 or more matches in Google Scholar instead of the expected single match to the original paper, I will try more quotes to see if more sentences from the newer paper have other, older hits as well. Often, there is only one sentence, so that is not of concern. But if there are more sentences, this might be a copycat suspect.
Of course, you can use regular Google to search the non-scientific rest of the internet, including Wikipedia pages which often serve as a source for plagiarized text.
SimTexter
Once text from a suspect paper has multiple hits as found by Google Scholar, it is time for a side-by-side comparison of the suspect paper and the source paper. For that, I use SimTexter.
SimTexter is a great and free tool developed in the lab of Debora Weber-Wulff, a professor for Media and Computing at the Hochschule für Technik und Wirtschaft in Berlin, Germany. Her blog “Copy, Shake, and Paste” is on my blog roll.
SimTexter is based on the SIM algorithm, developed by Dick Grune and Matty Huntjens.
To use SimTexter, you can either upload the text (as a .txt file) or copy/paste the text from the (older) source document in one of the two text boxes, and copy/paste the text from the (newer) suspect document into the other text box. You might have to do some formatting to remove some errors that might occur during copying from PDF files, such as removing hyphens that the PDF introduced at the end of a text line.
Then, you simply hit “Compare” and the output will appear on the screen. SimTexter is designed show blocks of contiguous text in one color, and will switch to a different color as soon as there is a break.
Here is an example of SimTexter’s output. You will see that the newer paper (on the right) changed one number in their abstract, and SimTexter’s highlighter will therefore switch to a different color.
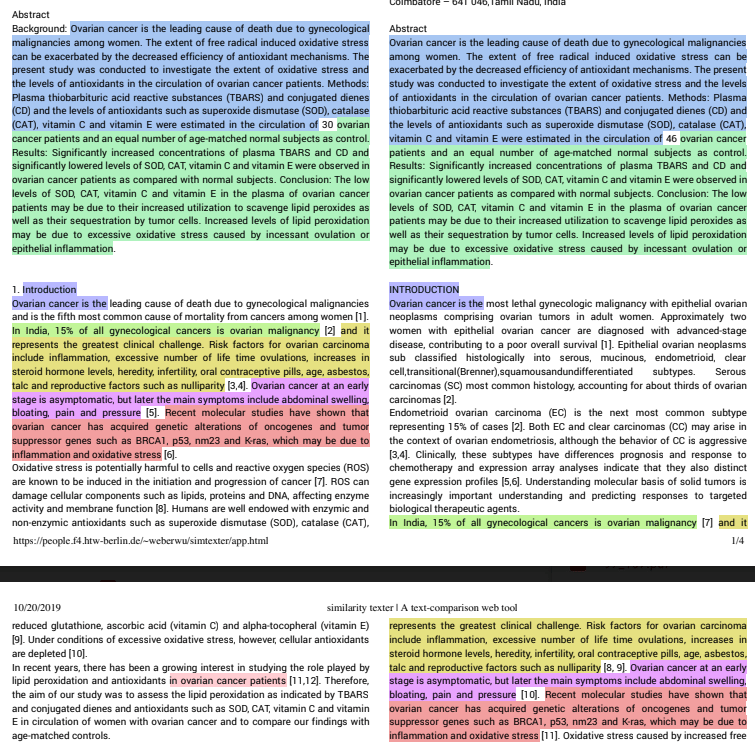
This works really well in the case where there is a suspicion that one paper has copied text from one particular source document.
However, the cases that I have encountered are almost always papers that are based on multiple other papers. So, although I do my primary analysis in SimTexter, I then manually color the suspect text in Google Docs or MS Word, using the same color for each different source paper. That is a lot of work!
Here is an example of the same suspect text shown above, after I manually highlighted it. In this case, there were only three different source papers, so I used green, yellow, and purple for each different source. As you can see, there is almost no original text in this paper. Most of the text appears to have been taken from the three source papers listed at the bottom. None of these source papers were listed in the references.

Other tools
Free: SEO Small Tools has a good, free plagiarism tool. It does not work well for scientific text, though. The abstract shown above was marked as only 23% similar to the NCBI abstract, and the tool does not have access to scientific papers other than the abstracts.
Free: FixGerald. Similar to SEO Small Tools, it might not find similarities to scientific papers that are not open access.
$$$: Grammarly has a plagiarism tool. I do not have an account (remember that I do all this work unpaid!), so I do not have any experience with the software.
Other people have reported working with Plagramme and CheckText, both free, but I have no personal experience with it.
$$$: For large-scale checking of many documents, iThenticate is the leading software. Together with TurnItIn (made by the same company) these are used in lots of US high schools and universities as well as scientific publishers. It will check all the text for you using their own database filled with scientific papers, and send out a report with the percentage of copied text, and from which sources. Unfortunately it is very expensive.


Thanks!
LikeLike
Thanks!
LikeLike
Lovely
It is realy helpful for journal editors and reviewers like me. I will try the tools soon.
LikeLike
Your generosity in sharing your knowledge, experience, and tools, is incredibly valuable, Elisabeth. Genuine thanks for making the world a better place. Vive l’intégrité!
LikeLike
TurnItIn doesn’t work very well on the newer types of plagiarism such as this:
https://andreasplagiarism.wordpress.com/2020/12/02/andreas-theodorou-committed-plagiarism-in-his-phd-thesis/
LikeLike