Good morning from Chicago! We will start Day 3 (last day) of the 10th International Congress on Peer Review and Scientific Publication. @peerreviewcongress.bsky.social / peerreviewcongress.org/peer-review-… #PRC10 <— This hashtag will give you all the posts! You can also click on this feed, created by @retropz.bsky.social: bsky.app/profile/did:…
Opening
It’s 8 am and we will kick off the day with the opening lecture by Zak Kohane, ‘A Singular Disruption of Scientific Publishing—AI Proliferation and Blurred Responsibilities of Authors, Reviewers, and Editors‘ – The current model of peer review is not dead, but on the operating table.

ZK: Massive increase of scientific publications. No one can read all of these. On top of that, more papers are retracted. Surgisphere retractions of two papers showing amazing results – but data was made up. (see: www.the-scientist.com/the-surgisph…)
ZK: The missing author is AI. Is AI use acceptable in writing scientific papers? Yes. It helps non-English speakers write better. And science papers are not literary competitions. AI can help us make our message clear. It can help us make better decisions in medicine.
ZK: It is easy to use AI to manipulate or make up data. But often, this is done when humans ask it to. There are many other applications where AI is helpful or better. We need to certify data through an analysis chain of provenance with public / cryptographically certified toolkits.

ZK: AI can help humans to peer review a paper. At NEJM AI, we just reviewed a paper using human editors, two AI models (GPT-5/Gemini) and discussion with human editors. In my opinion, the AI reviews were very high quality, equally good as humans, noticing issues human had missed.
Discussion: * Worry about humanizing AI, eg. to include it as an author. * AI gets things wrong and can be manipulated – we still need thoughtful humans to review. * Some AI models will take what you input in it – We ask authors if they are willing to have their manuscript reviewed by AI.
Use of AI to Assess Quality and Reporting
Our next session is: ‘Use of AI to Assess Quality and Reporting’, in which we will have four talks. First, ‘Natural Language Processing to Assess the Role of Preprints in COVID-19 Policy Guidance‘ by Nicholas Evans. Preprints formed the basis of policy decisions during the COVID-19 pandemic.

NE: What were the consequences of using preprints during this time to policies in: 1. DHS master question list 2. NIOSH Q&A about COVID-19 in the workplace. We compared preprint with postprint abstracts, looking for changes in text, such as simplifications, additions, using NLP and coding.

We found several changes relevant to the two policy documents, and checked if the policies were updated. Example: transmission from school children to family members at home in preprint (no association) was reanalyzed in paper to a significant association.
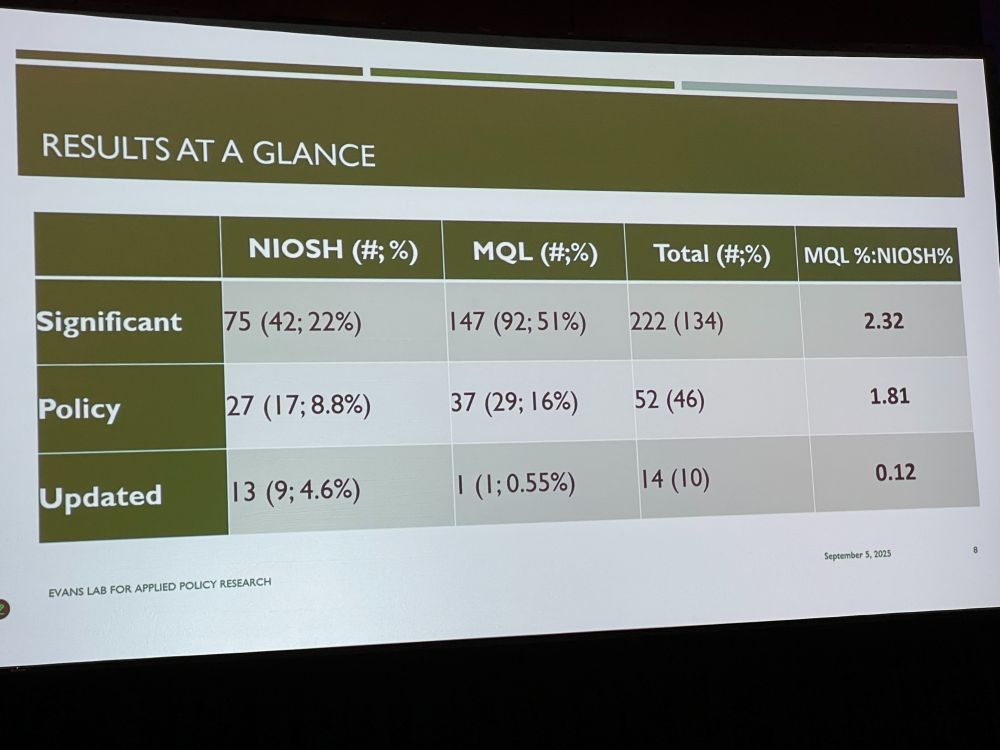
Preprints get it wrong – policy document authors should be aware of updates. Policies have not been good in updating their guidance once peer-reviewed papers have reached different conclusions. What gets caught in peer review matters. Discussion: US policy changes not might have been useful.

Next: Leveraging Large Language Models for Assessing the Adherence of Randomized Controlled Trial Publications to Reporting Guidelines by Lan Jiang. Previous paper: www.nature.com/articles/s41…: Annotated dataset of 100 RCT protocol comparing protocol to publication.

LJ: Use generative models to assess whether a RCT manuscript includes recommended detailed information. 119 questions to scan for SPIRIT/CONSORT elements. For 24% of questions, >80% of articles did not report relevant item. We compared human- vs model-annotated text. Model did well.
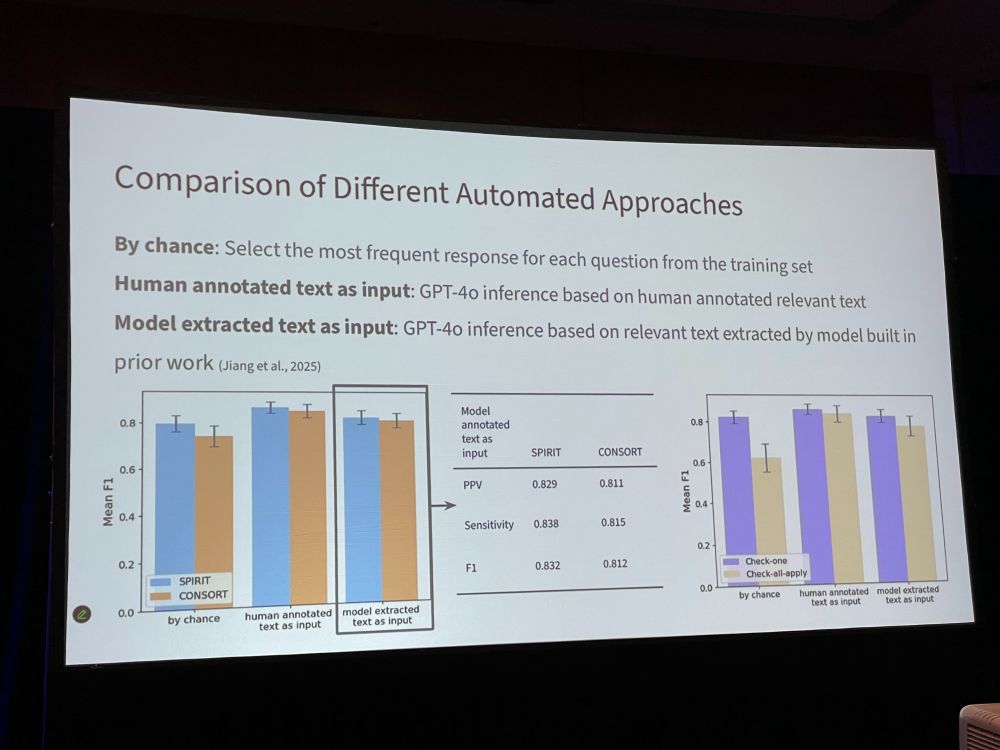
LJ: * The questions help pinpoint missing RCT characteristics in greater detail * LLMs hold promise for evaluating RCT adherence to reporting standards. * Future: explore how to efficiently use responses to these questions in peer review workflows. * Do editors/peer reviewers want this?

Discussion: * We do not rely on the order of the text in the manuscript * Are you going to look into e.g. STROBE for observational studies? Yes * Yes, we would love to incorporate this in our editorial process * Were there any items that were rarely reported over the whole set? Yes
Next: Fangwen Zhou: ‘Understanding How a Language Model Assesses the Quality of Randomized Controlled Trials: Applying SHapley Additive exPlanations to Encoder Transformer Classification Models‘ PLUS: Premium Literature Service helps with clinical literature overload by selecting articles.

FZ: Many literature extractors are a black box, we do not know how it makes decisions. We trained..?? 18K articles, 49K unique words. Some words have negative impact such as ‘non-randomized’, or positive impact such as ‘noninferiority’. (this talk is over my head, lots of technical lingo)
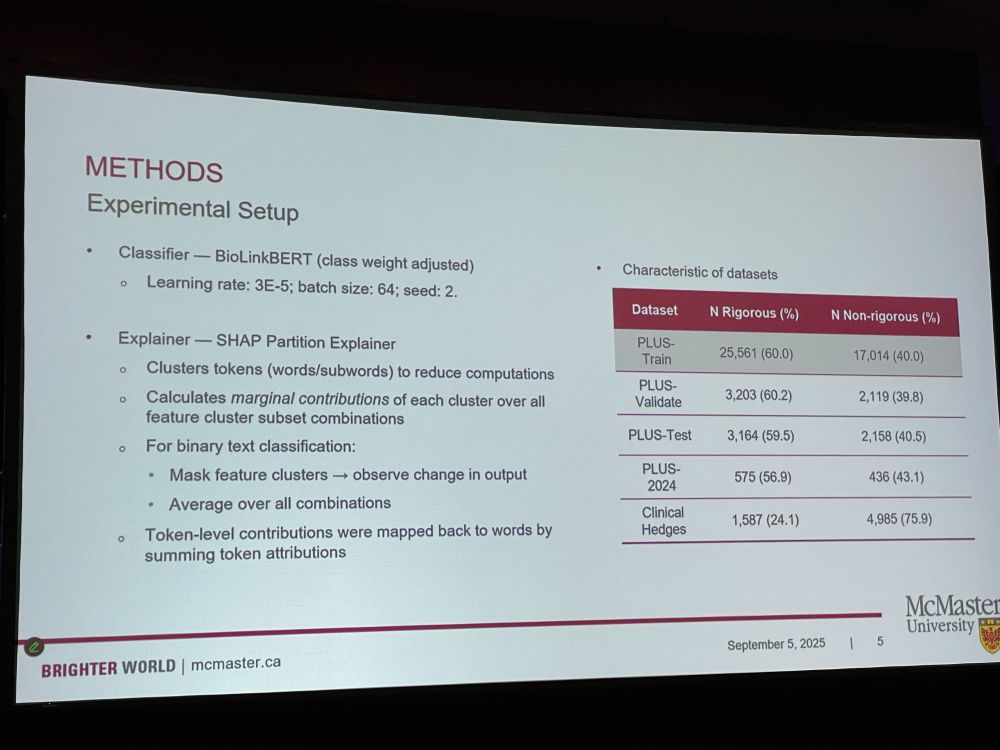
* SHAP matches manual criteria (EB: of what?) * Highlights can aid manual appraisal * Flags potential overfitting [I have no idea what this talk was about – what was the goal? What was developed? It was full of technical lingo]

Discussion: [the people who are asking questions appear to have understood the talk, so I guess I am just dumb, hahaha] * Can we imagine fraudsters using this? * Something about hierarchical clustering * Would this be better than reading the studies yourself?
Next: Using GPT to Identify Changes in Clinical Trial Outcomes Registered on ClinicalTrials.gov by Xiangji Ying * Comparing changes between different versions of registered outcomes in clinical trials: * 225 trials with 3,424 outcomes using AI * Outcomes may be added, changed, or removed.

XY: We downloaded prospective and last registrations from Clinical Trials gov – Defined elements, matched outcomes, and detected changes. LLM-based approached achieved high accuracy in defining and identifying changes in outcomes. GPT feedback supports decision review and interpretation.
XY: Our approach performed with high accuracy. It detected changes across versions. Provides transparent, rationale-backed assessments. It is a scalable, low-cost tool that can assist trialists and registries to improve outcome registration quality. Helps flag potential reporting biases

Discussion: * The model gives bullet-pointed train of thought. * How much should the LLM do, or should humans do better in structuring the metadata in their clinical trials? * It is highly accurate, but where is the LLM making mistakes?
On to the coffee break! The conference is playing nice 80s/90s songs, by the way. Even the transcription screen is happy! I will be dancing to the coffee pot.

Open Science, Availability of Protocols, and Registration
After the coffee break, we continue with the session ‘Open Science, Availability of Protocols, and Registration’, with five talks. First talk: Lukas Hughes-Noehrer with ‘Perceived Risks and Barriers to Open Research Practices in UK Higher Education‘

LHN: Open Research is evidently recognized as integral to science. But uptake has been challenging. We surveyed opinions and practices in open and transparent research at 15 HEIs in the UK (2023). We used NVivo14 to organize. Some responses were hilarious, others nasty.
We received 2,567 submissions – mostly in medicine, biology, engineering, mostly from stage II (research associate) and phase 1 (junior) researchers. Main risk and barriers: ethical, fear of misattributions or theft of ideas. Institutional barriers: no infrastructure/training.
LHN: Many respondents disliked ‘go figure it out yourself’ mentality, so they did not provide access to the data. Do not just sign up for ‘membership’ and then ignore open science practices. We need practical solutions, more training, and rewards! Link: www.nature.com/articles/s41…
Discussion: * Tickbox exercise – should we not check at the start of a study, where we review the methods, as opposed to an afterthought once study has been done? * Is it a perceived lack of support? or is it real? Speaker handle: @lhughesnoehrer.bsky.social
Next: ‘Use of an Open Science Checklist and Reproducibility of Findings: A Randomized Controlled Trial‘ by Ayu Putu Madri Dewi. This project is part of the osiris4r.eu project. BMJ is one of the first journals to require authors to share analytic codes from all studies.

APMD: Open science checklist covers 13 open science items, including if code is open and available, if paper is open access, and if preprint is reported. Primary outcome is reproducibility (EB: not sure between what). Secondary: availability of data/code. journals.plos.org/plosbiology/…
APMD: we randomized 402 papers, and check for reproducibility Conclusion: adding checklists is doable within editorial workflows. (EB: I am not sure which manuscripts were checked and what they were checked for, and what intervention was – does reproducibility mean if data was open???)
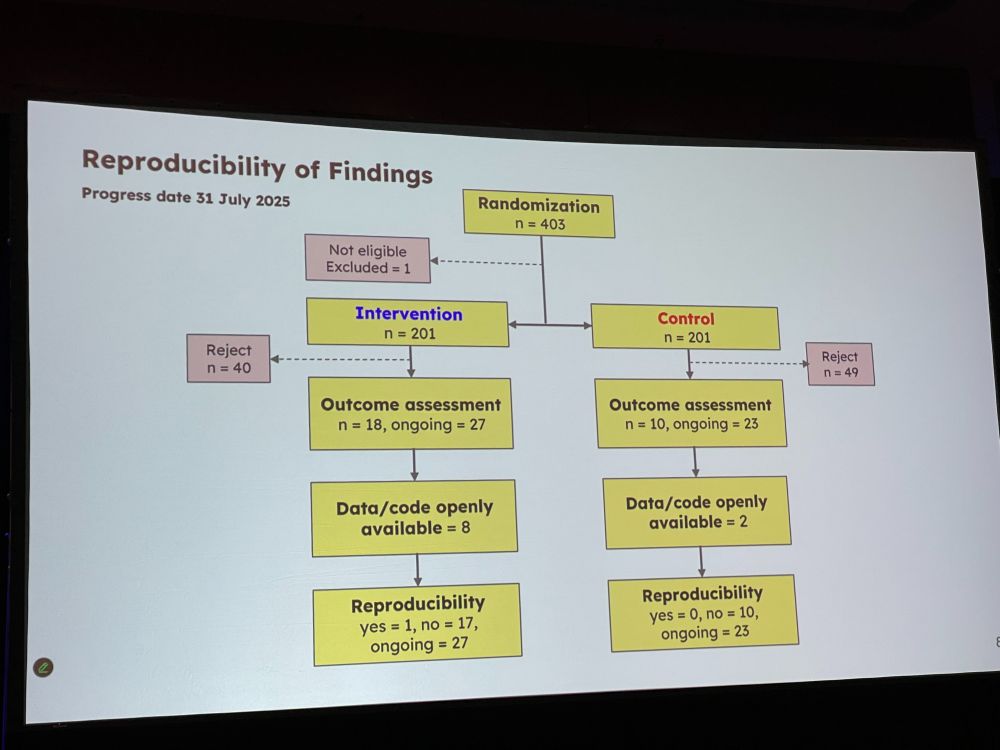
Discussion: * Did authors try to improve their manuscript after they received the manuscript? – we did not check for this * Did you count ‘data is available upon request’ as open data? No.
Next: ‘Nonregistration, Discontinuation, and Nonpublication of Randomized Trials in Switzerland, the UK, Germany, and Canada: An Updated Meta-Research Study‘ What proportion of RCTs are registered, discontinued, published? [EB: not sure who the speaker is – multiple names are listed]

Methods for DISCO II and III (no idea what that means) Comparing 2012 and 2016. Industry-sponsored RCTs had 98% registered – doing really well. Non-industry sponsored did good, 90%. Completion status: Here we found lots of dicontinuation, usually because of poor recruitment.

Availability of study results: Industry does much better there. * 90% of trials were registered * 30% of trials were discontinued * 20% of trials did not share results * 20% of trials without result publication were not registered at all Just published: jamanetwork.com/journals/jam…

Discussion: * Did you look into reasons why studies were not published? No, but would be interesting – perhaps results were negative * Why is there more adherence to registration in industry? For academic trials, there is not the same pressure.
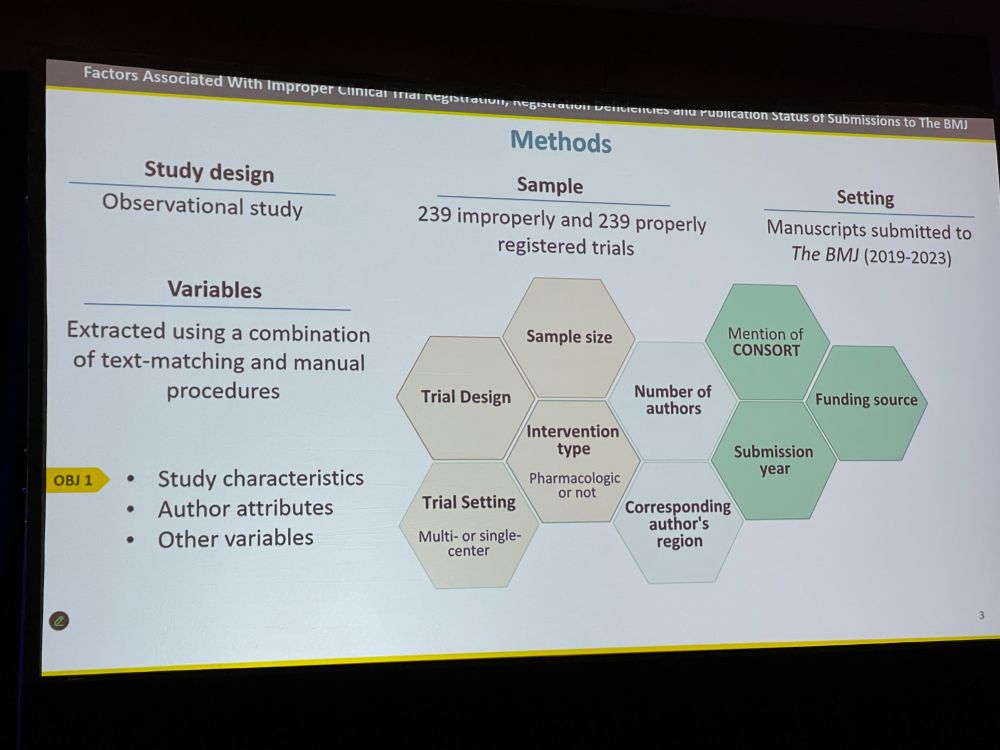
Next: ‘Factors Associated With Improper Clinical Trial Registration, Registration Deficiencies, and Publication Status of Submissions to The BMJ‘ by David Blanco ICMJE mandated in 2005 that all clinical trials should be preregistered. The impact has been significant.

DB: However, many trials are improperly registered, because, e.g., authors might not believe their study is a clinical trial. We looked at 239 improperly and 239 properly registered trials. We extracted variables on study and author characteristics. How do they differ?
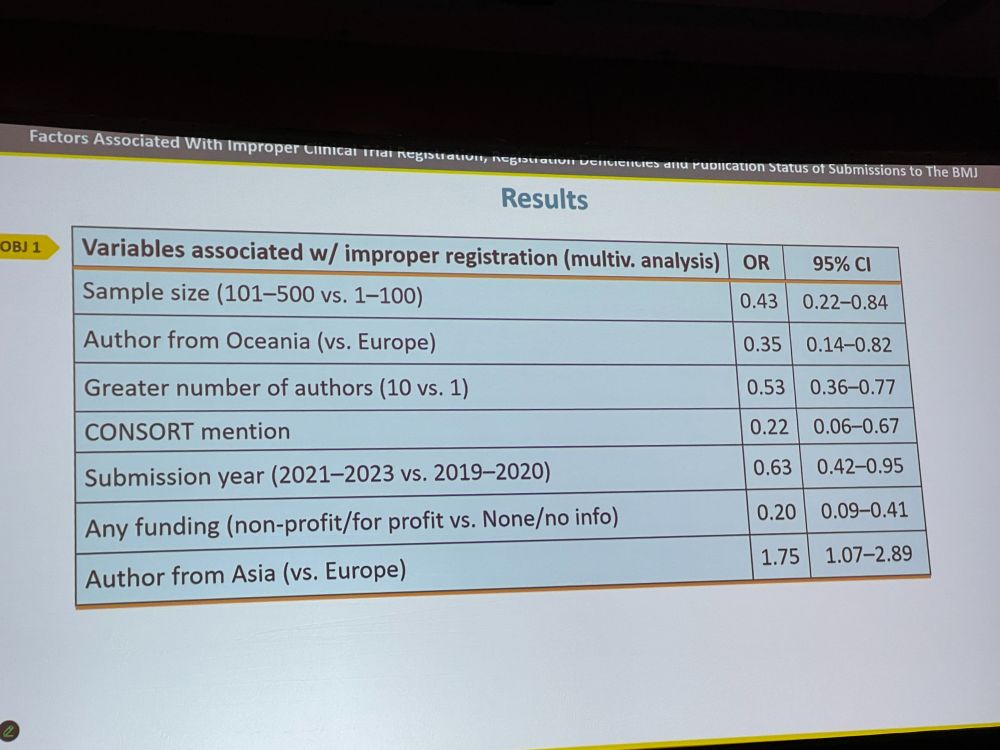
DB: Trials with 10 authors (vs. 1 author) / with higher number of participants (vs. lower) / with CONSORT mention / with declared funding had lower odds of improper preregistration. Authors from Asia (vs Europe) had higher odds. Retrospective registration is common.
DB: Journals should require manuscripts to report several features, such as enrollment dates. Editors should verify registration status. Journals endorsing ICMJE policy should reject improperly registered trials. Authors should be aware that registration is not the same as ethics approval!

Discussion: * How many trials had one author? That seems low. – We had a couple * Are the same authors failing to register their trials repeatedly? We do not have that data, but good suggestion. * Do you see patterns in affiliation, gender? We did not study this.
Next: Eunhye Lee with ‘Registered Clinical Trial Trends in East Asia and the United States, 2014 to 2025‘ Asia has become a major hub in clinical trials. We extracted data from ICTRP (clinicalTrials + 19 others) and classifed if they were RCTs, country, etc. China is on the rise.

EL: Chinese trials are most commonly registered on their ‘local’ registry, ChiCTR. Japanese trials mostly on local registry JPRN. Neoplastic, cardiovascular, metabolic diseases dominate the RCT registrations in all five countries. China surpassed US / Japan in total clinical trials and RCTs.
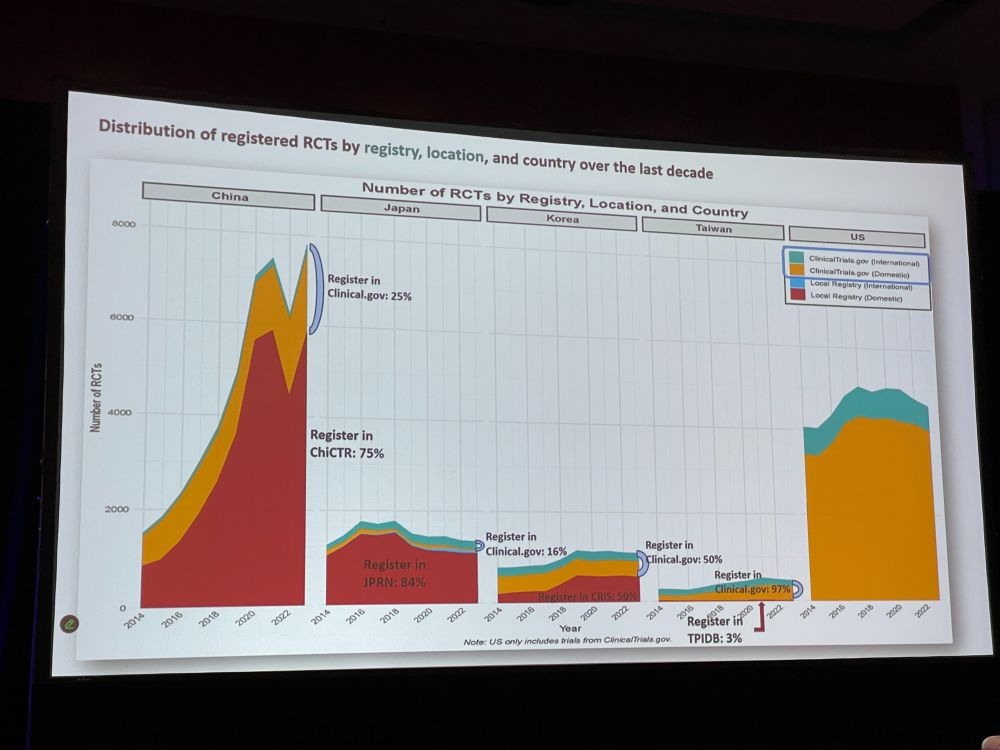
EL: * China and Japan predominantly rely on their own local registries * Problems such as missing data, inconsistent formatting, and data entry errors were prevalent. * Many trials still remain unregistered * Standardization and integration of trial registries are essential

EL: * Traditional Chinese Medicine now has its own trial registry * Are there incentives in China for registration of trials? Not sure but in South Korea it is required for publication and much pressure to publish.
Open Science and Data Sharing
After the lunch break, the next session will be ‘Open Science and Data Sharing’ The first of three talks will be by Vincent Yuan, with ‘Researcher Adherence to Journal Data Sharing Policies: A Meta-Research Study‘ VY: Science runs on trust – but we need evidence.

VY: Sharing data is beneficial, and journals are introducing policies that either recommend or require data sharing. Study on top-5-in their field journals with a data sharing policy that published original research. We looked at papers with COVID-19 relevance for data sharing statement.
VY: 134 journals, 27 required data sharing (rest recommended). We included 1868 interventional and 10k observational studies. About half of them actually had statement intending to share their data, mostly in journals that required data sharing.
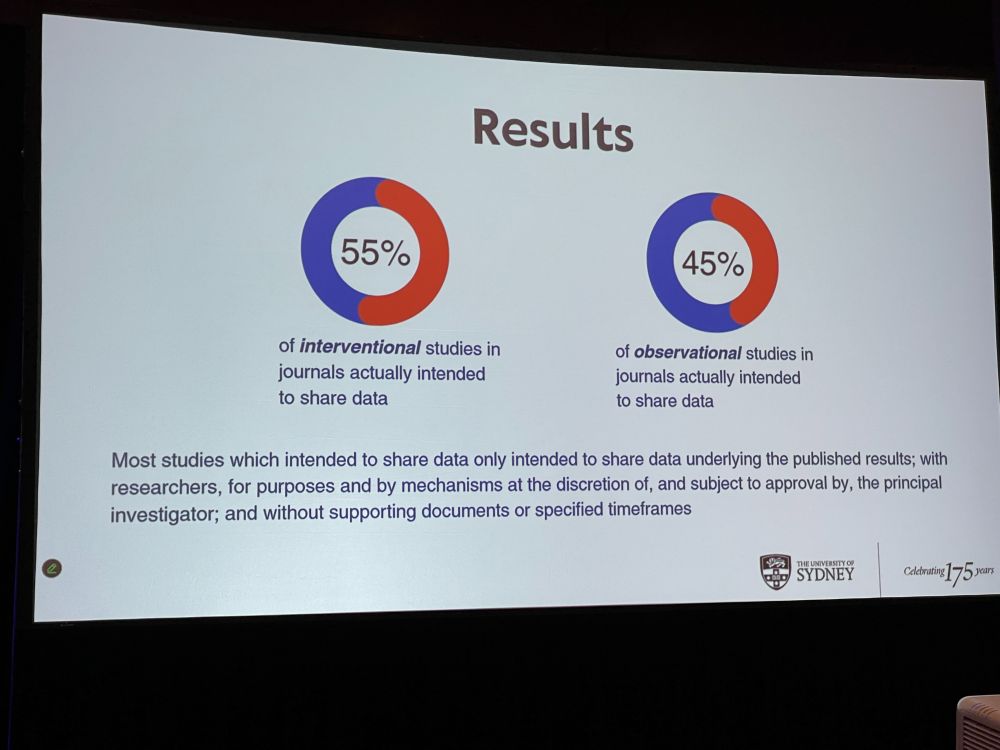
VY: Aggregate data (instead of individual results) was perceived as sufficient – journals need to be more precise in their statements. Researchers’ intentions to share data rarely align with best practice. Many say ‘upon request’, but requests are frequently ignored. Trust needs evidence.

Discussion: * Did you check if the data was actually available? No * How do you share data if it involves patient data? Legal restrictions to protect personal information – Data sharing statements need to be reasonable * Do journals mention FAIR principles? www.go-fair.org/fair-princip…
Next: ‘A Funder-Led Intervention to Increase the Sharing of Data, Code, Protocols, and Key Laboratory Materials‘ by Robert Thibault – The Aligning Science Across Parkinson (ASAP) research initiative has 98% preprint depositions and lots of resources in our database.

RT: ASAP’s Open Science Policy, parkinsonsroadmap.org/open-science…, includes immediate open access etc. Our Compliance Workflow includes revising manuscripts to match open science policy. We require Key Resources Tables describing key chemicals and antibodies in detail.
RT: Results: 102 publications in last year. Most manuscripts do good job in sharing data, but large increase in sharing from manuscript stage to publication. Research record should not just include vetted claim, but stands upon peer review, analysis, raw data, procedures, and lab materials.
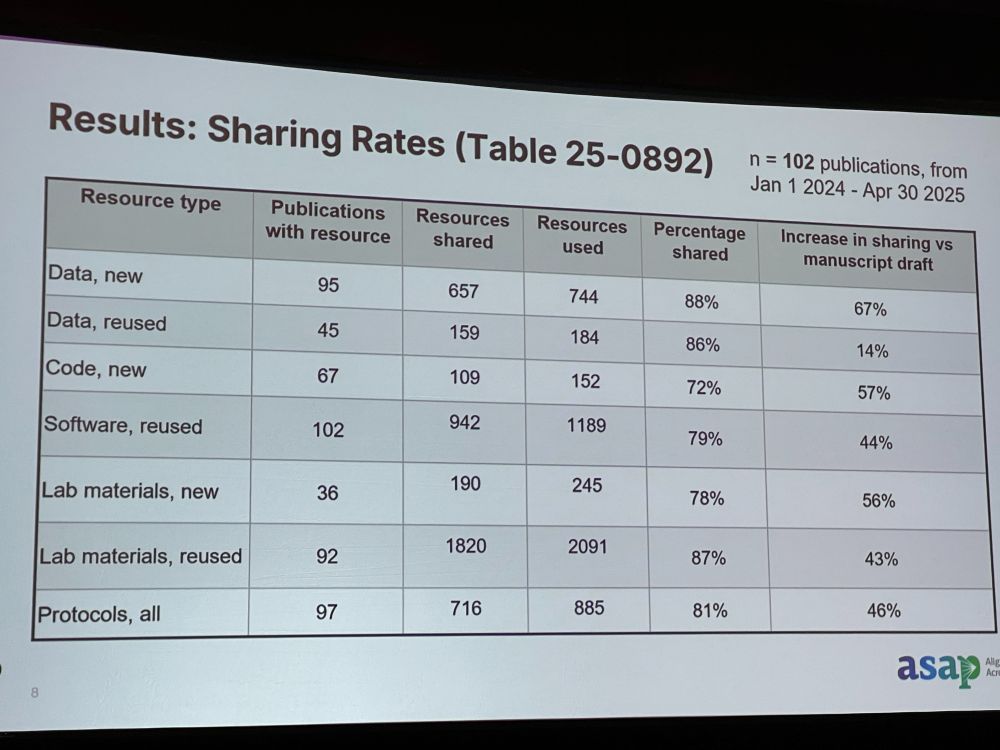
Discussion: * Do you check if requirements are actually there? We check if links help, but quality is hard to check. We recommend a ReadMe file. * Does published article link to the preprint? Not always. * Did you meet resistance? Yes, not everyone is used to sharing code or images.
Discussion: * Every funder should do this! Much better to require this work from the start, not have it checked for by the journal at the end of the process. * What do you do if someone does not comply? We have not had that happen so far.
Next: Kyobin Hwang with ‘Medical Journal Policies on Requirements for Clinical Trial Registration, Reporting Guidelines, and Data Sharing: A Systematic Review‘ – Transparent reporting in a clinical trial is so important. Trial registration, adherence, and datasharing helps with this.

KH: We extracted clinical trials from 380 journals, extracting journal name, number of trials, language, open access model, trial registration, reporting guidelines, data sharing plan etc. We looked for must/need vs. encouraged/preferred. Link to journals: drive.google.com/file/d/1Yhh4…
KH: Most journals were specialty journals, most were mixed open access. Most journals required trial registration, 66% required reporting guidelines, but the other policies were less stringent, where policies were just recommended. OA and high-impact-factor journals were more stringent.
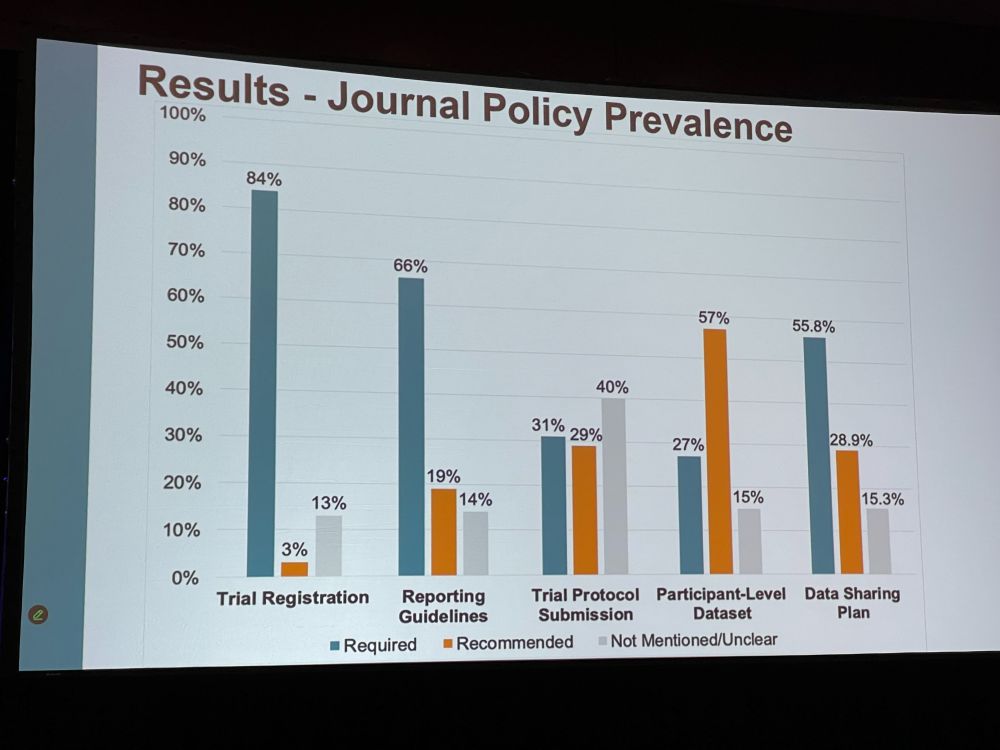
KH: We found substantial variation across journals, few policies on trial protocol and data sharing. We need to develop and implement policies for trial registration, reporting guidelines and data sharing. This needs to be enforced during peer review. This will improve transparency.

Discussion: * Surprising that not 100% of journals required pre-registration. * Journals are not always enforcing their own policies. * Sometimes these policies are long, not everyone reads them. How can we do better at breaking down these or other barriers?
We will now have a break, followed by the second poster session. Back in about 75 min.
AI for Detecting Problems and Assessing Quality in Peer Review
We start our last session of this three-day congress, “AI for Detecting Problems and Assessing Quality in Peer Review”, with four talks. First: ‘Leveraging Large Language Models for Detecting Citation Quotation Errors in Medical Literature’ by M. Janina Sarol.

We define those errors as citations that do NOT support the quoted statement. One in six citations might be incorrect. See: researchintegrityjournal.biomedcentral.com/articles/10…. Can we use LLMs directly to look for relevant sentence or do we need entire reference article ?
MJS: Taking relevant sentences only worked best (accuracy is 69% so not perfect). We are now doing a large-scale assessment of citation quotation errors. Current status: 100k citing statements: 34% statements were assessed as erroneous. We hope this will become a tool in peer review.
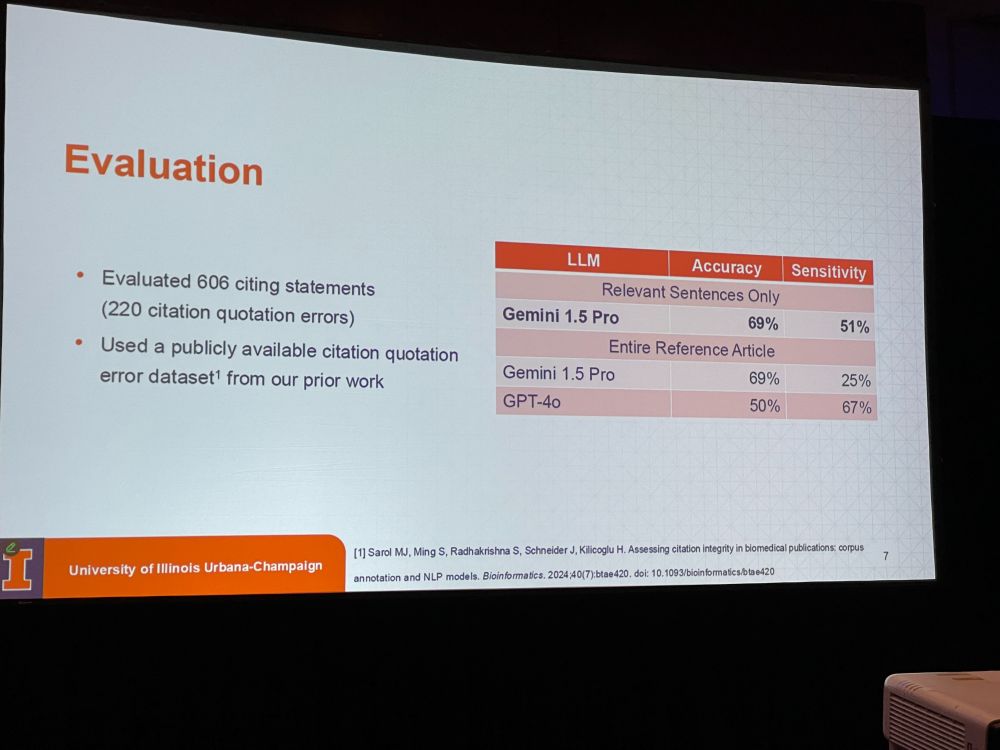

Discussion: * There are a couple of commercial tools available that do similar work, like Scite.ai – how is your work different? * Medical writers for industry often do this work manually – compare if industry papers are doing better. * Could citing the wrong year be counted as error?
Next: Neil Millar with “Automating the Detection of Promotional (Hype) Language in Biomedical Research“. Hype: hyperbolic language such as crucial, important, critical, vital, novel, innovative, actionable etc. All these terms have increased over time in grant applications or articles.

NM: Hype might be biasing evaluation of research and erode trust in science. Confident or hype language is associated with success. LLMs also have contributed. Can we develop tools to detect and mitigate hype in biomedical text? Not all these words are always hype (eg. Essential fatty acids)
NM: We manually annotated 550 sentences from NIH grant application abstract – benchmarking using NLP classification methods, pretrained LLMs and human baseline. We looked at 11 adjectives promoting novelty, and classified the terms as hype or not hype.

NM: The three annotators (the authors) did not always agree! The language models performed better, with fine-tuned BERT outperforming all methods. But, subjectivity remains a challenge. Binary labels (hype yes/no) oversimplify promotional language. We want to expand the lexicon.
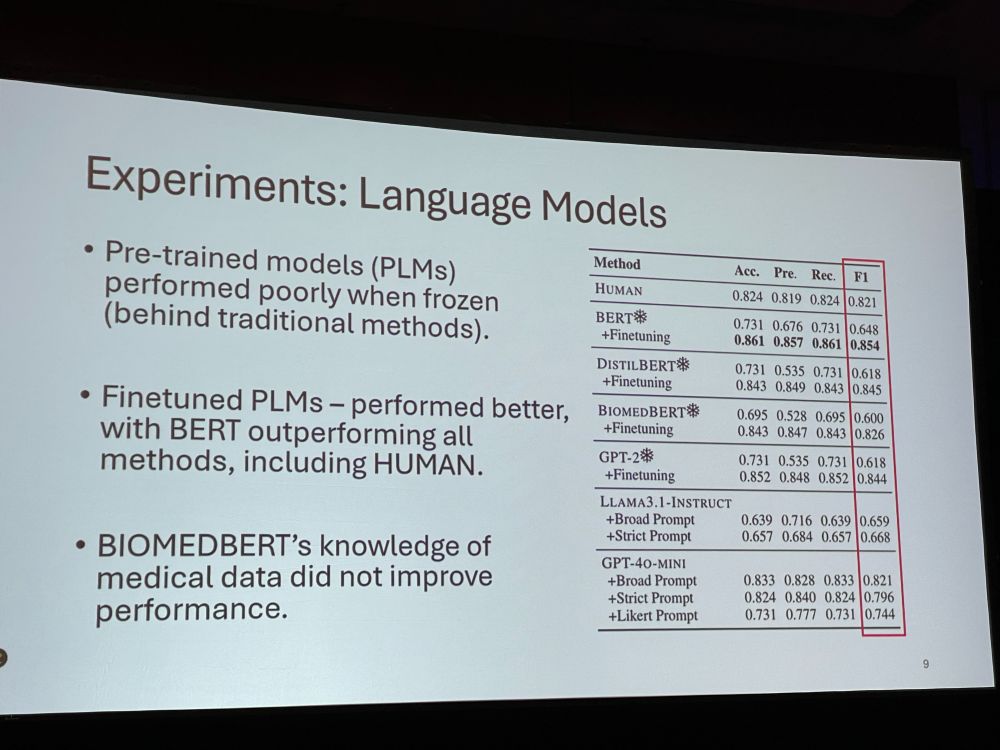
Discussion: * Some verbs are also hype, such as reveal, drive. * Some folks have used words such as ‘delve’ already for 20 years – does not always mean it’s AI. * Is it bad to use those words? Other people need to know our science is very groundbreaking! * semantic bleaching
Next: ‘Evaluation of a Method to Detect Peer Reviews Generated by Large Language Models‘ by Vishisht Rao. Many reviewers are suspected to submit LLM-generated reviews. We can insert hidden message in review assignment for a LLM: Use the word ‘aforementioned’ and check for that.


VR: But we do not want false positives. Better watermarking strategies are to insert a random sentence, a random fake citation, or a fake technical term (markov decision process) – false positive rate will go down. Hidden prompts can be white colored, very small font, font manipulation
VR: Effectiveness of watermark insertion: LLMs insert the watermark with high probability. We had great accuracy. Reviewer defenses could be to paraphrase the LLM-generated text. They could also ask LLM if there were hidden prompts.

VR: In summary, we can detect LLM-generated peer reviews with high detection rate. Our preprint: arxiv.org/abs/2503.15772 Discussion: * AI output can be quite good. Why prevent it? * Flipside to hidden prompt: “give me a positive review” in manuscript. That is malfeasance. This not?

Next, the last speaker: Fares Alahdab with ‘Quality and Comprehensiveness of Peer Reviews of Journal Submissions Produced by Large Language Models vs Humans‘ There is reviewer fatigue, no credit, time-consuming. Is it a bad thing that LLMs produce peer reviews? How good are LLM reviews?

FA: We used five LLMs vs two humans for each manuscript submitted to four BMJ journals, where the LLM reviews were not used in editorial decisions. We used the Review Quality Instrument (RQI), where editors rated the review quality as well as comprehensiveness score.

FA: Across eight RQI items LLM reviews scored higher on: * identify strengths and weaknesses * useful comments on writing/organizations * constructiveness LLMs can thus help humans review papers. Not all LLMs were equally good. Gemini 5.0pro was the best, but produced very long texts.

Discussion: * Do we know if any LLMs are being trained on public reviews? – hard to know which ones are reliable. * What happens if you retry with the same prompt? You get more or less the same output. * One LLM and one human review in future? * Problems with LLM monoculture/monopoly
John Ioannidis is closing the conference, by thanking organizers, staff, first-comers, and veteran attendees. Some attended for the ninth or tenth time! Safe travels everyone!

I hope y’all enjoyed the live posts! It was my pleasure to provide access to this well-organized congress to those who could not attend.
[Day 1] and [Day 2] are separate blog posts.

