How does one scan for duplicated images in scientific paper, and how can one determine if those are a sign of misconduct? This post will give some background about my past and current work on this topic.
A study on 20,000 papers
In 2014-2015 I checked a set of 20,621 biomedical papers that contained photos, such as Western Blots, gels, or microscopy images. I also scanned flow cytometry plots, since they contain unique constellations of datapoints. About half of the papers that I scanned came from PLOS ONE, an Open Access journal that has an easy website to search and flip through figures. The other half of the 20,000 papers used for this screen had been published in 39 other journals with a range of impact factors.
During my scan of a paper, I would not read the text, but just focus on the photos. I would look for duplicated panels within the same paper (e.g. a Western blot from Figure 1B reused in Figure 5C), within the same figure (e.g. two microscopy photos representing different experiments, but with a clear overlap), or duplications within the same photo (e.g. lanes 1 and 5 in a Western blot strip that look identical). I would only count these duplications “inappropriate” if the photos were used to represent different experiments. Most papers took only 1 min to scan, but papers from with a lot of different figures and panels might take up to 15 min.
I scanned all these 20,000 papers by eye, although I occasionally would use Preview to make an image lighter or darker to bring out more details.
Although the scanning was relatively fast, downloading all the papers or opening all the tabs, marking all the found duplications, building a spreadsheet, and writing reports took quite some time, and turned this into a nearly 3 year-long project. During the day, I was a staff scientist at the School of Medicine at Stanford University, where I did research on the microbiome of humans and dolphins. And at night and in the weekends, I scanned dozens of papers as a strange hobby project.
In this set of 20,000 papers, 782 (4%) contained inappropriately duplicated photos.
All my findings were confirmed by two Editors-in-Chief, Ferric Fang and Arturo Casadevall, independently from each other. If one of these two did not agree with my findings, which happened in about 10% of the cases I found, we did not count that as a duplication. But in 90% of the cases, my findings were confirmed by these experienced professors.
The three of us published this study in 2016 in mBio.
Three types of duplications
In our study we divided the duplications we found into three categories. This allows us to better speculate about what happened and whether there was any intention to mislead.
Category I duplications. Some duplications are “simple” duplications, where e.g. two panels look identical. These could be the result of an honest error, where the same photo or plot was inserted twice in a figure or paper by accident. However, in cases where several pairs of panels appear to be duplicated, one could wonder if this is a sign of sloppiness or laziness.
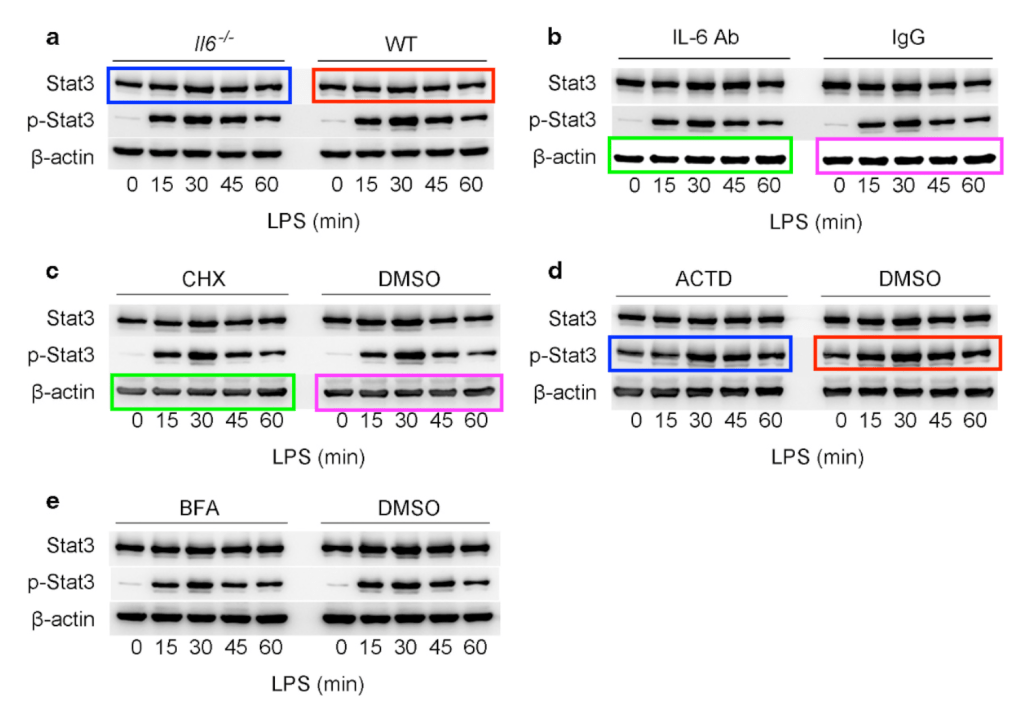
Category II duplications. In some other cases, panels are rotated, flipped, shifted, etc. These are less likely to occur as the results of an honest error, and more likely to be done intentionally, than Category I, simple duplications.
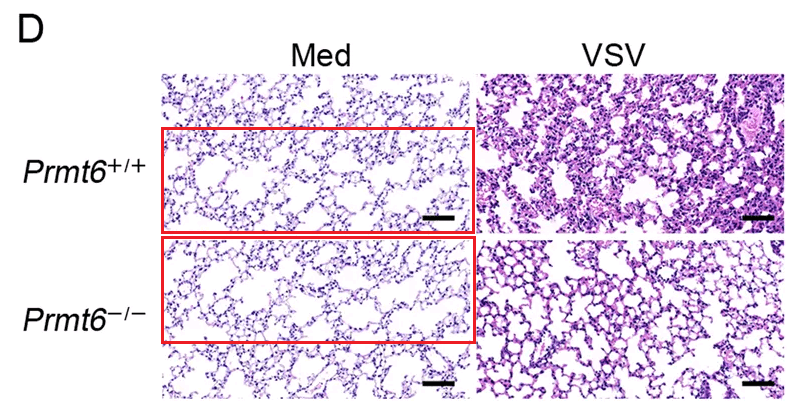
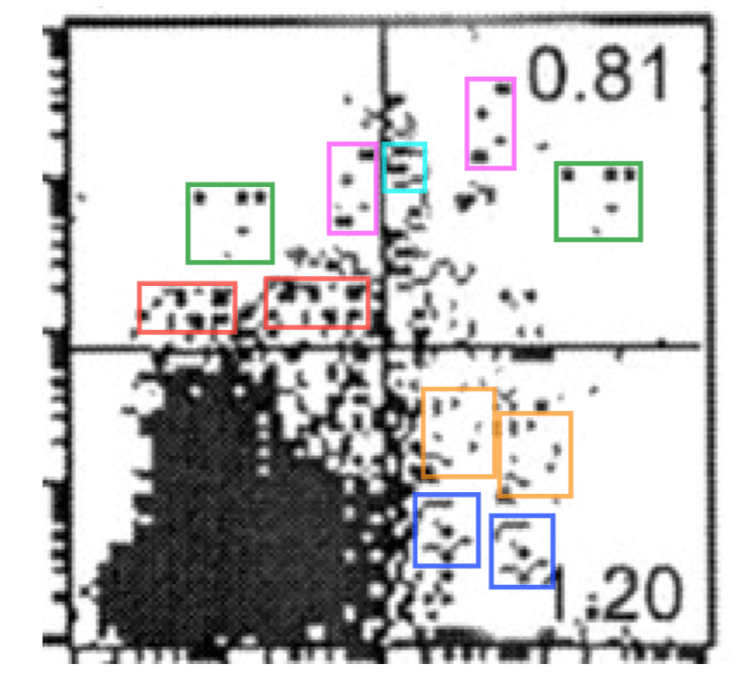
Category III duplications. Then, there are cases where features such as cells, bands, or groups of dots appear to be visible multiple times within the same photo or plot, or have taken from other panels to re-appear in a different panel. Most of these are very hard to explain by honest error, and more likely to be the result of an intentional alteration of a photo than duplications of category I or II. However, in rare cases, there could be certain artifacts or technical errors that might explain some of these repetitions.
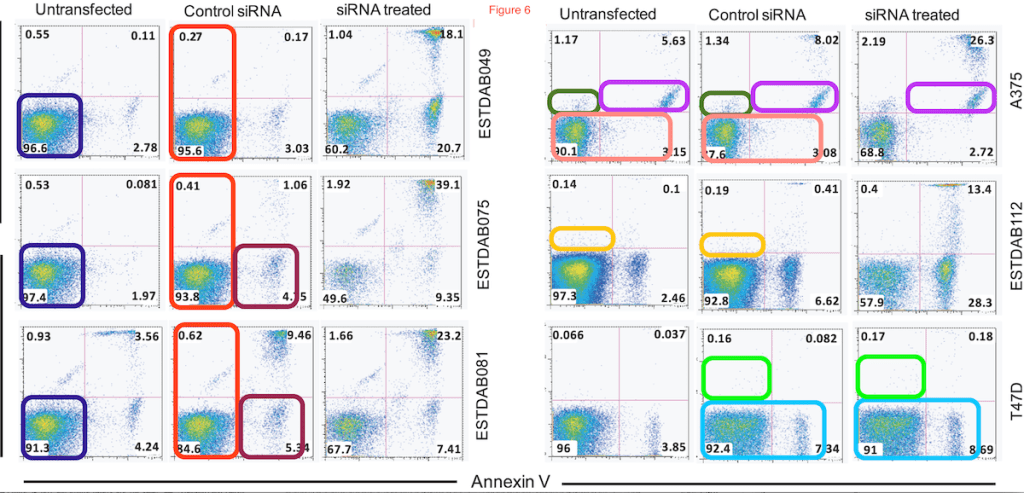
I also count it as a category III duplication if one part from a panel appears in a different panel. Here is such an example:
Following up on leads
All ~800 papers with duplicated images were reported by me to the journal in which they were published. This was in 2014 and 2015, so that I can now make up the balance of what happened to these papers, 5 years later. But that will be another post!
We also posted two follow-up papers, in which we looked at demographics and academic culture of a subset of the 800 papers, and another one where we looked at the time invested in handling and correcting papers with duplications after and before publication.
This study also yielded quite some interesting leads, in particular from authors who had multiple papers with duplications. I followed up on many of these leads by screening more papers, and found several “clusters” of papers with duplications that all came from the same author or lab. Now that I can work on on these cases nearly full time, I have discovered more and more of these clusters. Some of these clusters were very big, with dozens of papers by the same last author or from the same university. And some of them have recently made some headlines.
References
Bik EM, Casadevall A, Fang FC. The Prevalence of Inappropriate Image Duplication in Biomedical Research Publications. MBio. 2016 Jun 7;7(3). pii: e00809-16. doi: 10.1128/mBio.00809-16.
Bik EM, Fang FC, Kullas AL, Davis RJ, Casadevall A. Analysis and Correction of Inappropriate Image Duplication: the Molecular and Cellular Biology Experience. Mol Cell Biol. 2018 Sep 28;38(20). pii: e00309-18. doi: 10.1128/MCB.00309-18.
Fanelli D, Costas R, Fang FC, Casadevall A, Bik EM. Testing Hypotheses on Risk Factors for Scientific Misconduct via Matched-Control Analysis of Papers Containing Problematic Image Duplications. Sci Eng Ethics. 2019 Jun;25(3):771-789. doi: 10.1007/s11948-018-0023-7.


Would it help you to have a dataset with all the images already extracted for you, from all the relevant papers? I think it can be done for a few millions of them automatically, and at least you could spare the manual download and extraction.
LikeLike
Why not use computer vision algorithms to do the job…. Much faster.
LikeLike
She has addressed this a few times.
“For anyone who thinks that image recognition by software is easy. Google reverse image search thinks the left image is a whale.”
“I get a lot of remarks like these, but it must be much harder than you think, because no one has been able to show me software that is better than me. ”
“Not trivial at all. I have shared our dataset of papers with duplicated photos with several groups who all claimed they could easily write software. Never heard back from most of these.”
“Some groups, however, have stated they now have working or nearly-working software, but I have not personally seen or tested any of these. Maybe no one has dared to send it to me yet?”
“I am collaborating with several groups that are working on such software tools, which would be very valuable to have for publishers/journals. Better to find these cases before publishing.”
“Agreed, there are several academic and industry groups trying to work on this, but no software on the market yet (as far as I know) that can do this automatically. I have a dataset for anyone who things they have a tool to detect it!”
“But it is not unreasonable that publishers build in some screening for obvious errors in figures or tables before peer review or publishing, like most COPE journals screen for plagiarism. Hoping that image screening can be done by software!”
“I spot these by eye. It would be great if there was software to find these, though.”
“Having scanned ~30k papers manually, it would be great to have tool that journals can use in pre-publication process (like plag software)”
LikeLike
I wonder if this is something that civilians could be trained to do on a simple level, as in a Zooniverse project. There are a lot of projects there that consist of getting human eyes on images that computers don’t quite differentiate/see as well yet.
LikeLike